Original Database Definition: AdventureWorksCREATE DATABASE [AdventureWorks] ON PRIMARY
( NAME = N'AdventureWorks_Data', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\AdventureWorks.mdf' , SIZE = 180992KB , MAXSIZE = UNLIMITED, FILEGROWTH = 16384KB )
LOG ON
( NAME = N'AdventureWorks_Log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\adventureWorks.ldf' , SIZE = 133120KB , MAXSIZE = 2048GB , FILEGROWTH = 16384KB )
GOCreate a snapshot of the AdventureWorks database--Logical Name must be the same of the database definitionUSE MASTER
GO
CREATE DATABASE AdventureWorks_Snapshot_Aug
ON (NAME=N'AdventureWorks_Data',FILENAME='C:\Data\Adv_Snapshot_Aug.mdf')
AS SNAPSHOT OF AdventureWorksA user deleted many wrong records. USE AdventureWorks
GO
DELETE FROM Sales.SalesOrderDetail
WHERE SalesOrderID=43659
You want to revert it --if you have multiple snapshots created, drop all other snapshots except the AdventureWorks_Snapshot_Aug'USE MASTER
RESTORE DATABASE AdventureWorks FROM
DATABASE_SNAPSHOT='AdventureWorks_Snapshot_Aug'
You can restore only one row from the snapshot.USE AdventureWorks
ALTER TABLE Sales.SalesOrderDetail
Add tmp CHAR(3) NULL
GO
UPDATE Sales.SalesOrderDetail
SET tmp='A'
WHERE SalesOrderDetailID=1;
UPDATE Sales.SalesOrderDetail
SET tmp='B'
WHERE SalesOrderDetailID=2;
GO
USE MASTER
GO
CREATE DATABASE AdventureWorks_Snapshot_Sept
ON (NAME=N'AdventureWorks_Data',FILENAME='C:\Data\Adv_Snapshot_Sept.mdf')
AS SNAPSHOT OF AdventureWorks
GO
--12 records deleted
USE AdventureWorks
DELETE FROM Sales.SalesOrderDetail
WHERE SalesOrderID=43659
GO
--restore only one record
USE AdventureWorks
DECLARE @SalesOrderID INT;
DECLARE @CarrierTrackingNumber NVARCHAR(25);
DECLARE @OrderQty SMALLINT;
DECLARE @ProductID INT;
DECLARE @SpecialOfferID INT;
DECLARE @UnitPrice MONEY;
DECLARE @UnitPriceDiscount MONEY;
DECLARE @LineTotal NUMERIC(38,6);
DECLARE @rowguid UNIQUEIDENTIFIER;
DECLARE @ModifiedDate DATETIME;
DECLARE @tmp CHAR(3);
SELECT @SalesOrderID=SalesOrderID,
@CarrierTrackingNumber=CarrierTrackingNumber,
@OrderQty=OrderQty,
@ProductID=ProductID,
@SpecialOfferID=SpecialOfferID,
@UnitPrice=UnitPrice,
@UnitPriceDiscount=UnitPriceDiscount,
--@LineTotal=LineTotal,
@rowguid=rowguid,
@ModifiedDate=ModifiedDate,
@tmp =tmp
FROM
AdventureWorks_Snapshot_Sept.Sales.SalesOrderDetail
WHERE tmp ='A'
INSERT INTO Sales.SalesOrderDetail ( SalesOrderID,CarrierTrackingNumber,
OrderQty,ProductID,SpecialOfferID,UnitPrice,UnitPriceDiscount
,rowguid,ModifiedDate,tmp)
VALUES (
@SalesOrderID,@CarrierTrackingNumber,
@OrderQty,@ProductID,@SpecialOfferID,@UnitPrice,
@UnitPriceDiscount
,@rowguid,@ModifiedDate,@tmp )
GO
Restore a field value from a snapshotUPDATE Sales.SalesOrderDetail
SET OrderQty=100,
UnitPrice=200
WHERE tmp='A'
DECLARE @OrderQty SMALLINT;
DECLARE @tmp CHAR(3);
SELECT
@OrderQty=OrderQty,
@tmp =tmp
FROM AdventureWorks_Snapshot_Sept.Sales.SalesOrderDetail
WHERE tmp ='A'
UPDATE Sales.SalesOrderDetail
SET OrderQty=@OrderQty
WHERE tmp='A'
GO




 If a table do not have a clustered index defined, the data rows are in an unordered structure called
If a table do not have a clustered index defined, the data rows are in an unordered structure called 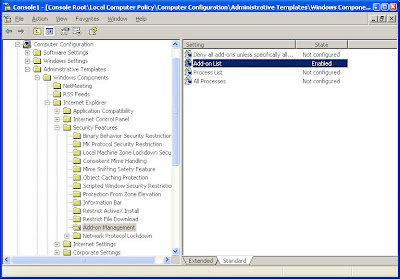
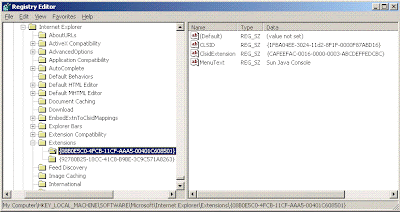
 Then, right click on the Registry Key and select Copy Key Name and Paste it to Addon List window--only keep the { } :
Then, right click on the Registry Key and select Copy Key Name and Paste it to Addon List window--only keep the { } :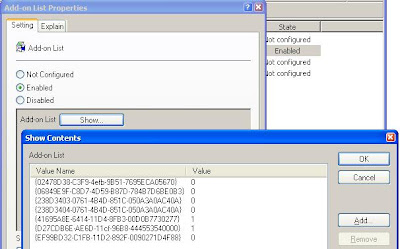

 EXECUTE AS SELF
EXECUTE AS SELF

 ---------------
---------------










{kind=link}
{kind=link}