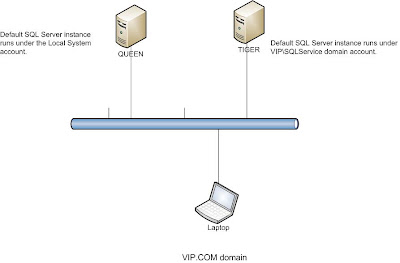
You must apply SQL Server SP2 on all SQL computers, including the clients.
- Creating a Linked server to TIGER SQL Server.
EXEC sp_addlinkedserver 'TIGER','SQL SERVER'
Making sure the security is set to self-mapping, as shown below:
Becaue the SQL Server Instance runs under the LocalSystem account, its SPN is automatically registered. You can check the SPN:
setspn -L QUEEN
Registered ServicePrincipalNames for CN=QUEEN,OU=Domain Controllers,DC=VIP,DC=COM:
MSSQLSvc/queen.VIP.COM:1433
Because the service account of TIGER SQL SERVER Instance is a domain user account without administrator privileges, you must register ServicePrincipalNames for CN=sqlservice,CN=Users,DC=VIP,DC=COM
setspn -A MSSQLSvc/Tiger.VIP.COM:1433 VIP\SQLService
- Creating two domain users: a1 and a2;
- Creating two logins for them in both SQL Server instances;
- In TIGER SQL Server, creating a database user in AdventureWorks database and assigning it the SELECT permission on AdventureWorks.Person.Address table;
- At laptop computer, login as user a1, open the query window that connects QUEEN SQL Server instance; Run the distributed query statement, SELECT TOP 6 * FROM TIGER.AdventureWorks.Person.Address
- At laptop computer, login as user a2, open the query window that connects QUEEN SQL Server instance; Run the distributed query statement, SELECT TOP 6 * FROM TIGER.AdventureWorks.Person.Address
No permission to run the statement.
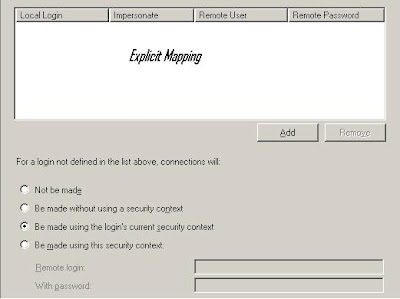
- Understanding the IMPERSONATE button
If Windows user mapping exists, distributed query goes ahead. Otherwise, not be made. Or Be made without using a security context; or Be made using this security context--specify a user account.
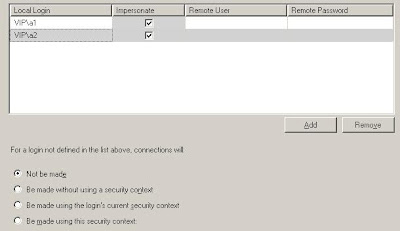
- Explicit-mapping without impersonating
EXEC sp_addlinkedsrvlogin 'TIGER',False,'VIP\a1','SQLuser','password'
EXEC sp_addlinkedsrvlogin 'TIGER',False,'VIP\a2','SQLuser','password'

The TIGER SQL SERVER instance must be in MIXED security mode. The remote user can only be a SQL Server login.
"Login Failed for user 'NT Authority\ANONYMOUS' LOGON" shows.
Reason:
Lou:SQL Server does not have a SPN for its SQL Server service registered.
"Login Failed for user ' ', the user is not associated with a trusted SQL Server connection".
Reason:Norton SQL Server does not have the account defined and no permission assigned.
SQL Server Log
"The SQL Network Interface library could not register the Service Principal Name (SPN) for the SQL Server service. Error: 0x2098, state: 15. Failure to register an SPN may cause integrated authentication to fall back to NTLM instead of Kerberos. This is an informational message. Further action is only required if Kerberos authentication is required by authentication policies."
When both SQL Server instances start using Local System account or with a domain account that is a member of Administrators group,
 How to enable the delegation tab shown above?
How to enable the delegation tab shown above?
- Raise the domain function level to Windows server 2003
- SetSPN -A MSSQLSvc/Queen.VIP.COM:1433 sqlservice
If you have multiple instances installed within the same server, you don't need the SQL Service SPN registration and the service account is trusted for delegation. Even I manually delete the SPN registration and disable the service account delegation, the self-mapping of linked server works fine as long as both instances have the Windows login name defined and the necessary permissions assigned.



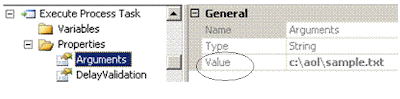

 Open the dbo.[SSIS Configurations] table, identify the row with Configuration Filter set to example1, modify the configuredValue, and rerun the package:
Open the dbo.[SSIS Configurations] table, identify the row with Configuration Filter set to example1, modify the configuredValue, and rerun the package: 
 Create an SSIS project;
Create an SSIS project;
 After the configuration, value of environment variable ConnectStr will replace the ConnectionString target property; The value of environment variable MyFile will replace the Arguments of Execute Process Task.
After the configuration, value of environment variable ConnectStr will replace the ConnectionString target property; The value of environment variable MyFile will replace the Arguments of Execute Process Task.
 Connection to AOL Folder manager will access the c:\sample1.txt, sample2.txt, etc.
Connection to AOL Folder manager will access the c:\sample1.txt, sample2.txt, etc.

 Double-click on Flat File Source and make sure that the column names are correctly mapped. And then, double-click on the OLE DB Destination, click on the Mapping, you should have the following:
Double-click on Flat File Source and make sure that the column names are correctly mapped. And then, double-click on the OLE DB Destination, click on the Mapping, you should have the following: Execute the package;
Execute the package; Double-click the Lesson 2.dtsx package;
Double-click the Lesson 2.dtsx package;

 Select "Connection to AOL Folder", Properties pane:
Select "Connection to AOL Folder", Properties pane:
 Step 2:Double-click on the Data Flow Task to navigate onto Data Flow pane
Step 2:Double-click on the Data Flow Task to navigate onto Data Flow pane
 You can save the package to SQL Server.
You can save the package to SQL Server. The BROWSER cannot deploy a report and cannot upload files (resources).
The BROWSER cannot deploy a report and cannot upload files (resources). What is a resource?
What is a resource?

 Other extensions have the quite similar explanation.
Other extensions have the quite similar explanation.
 ===
=== From report manager
From report manager 
 Second, make sure the SQL Server Agent service starts.
Second, make sure the SQL Server Agent service starts.

 Click on Layout tab
Click on Layout tab Deploy the report;
Deploy the report; Click on Layout tab, Report Menu--Report Parameters, this time select FROM QUERY with dataset:Title
Click on Layout tab, Report Menu--Report Parameters, this time select FROM QUERY with dataset:Title Deploy the report;
Deploy the report;



